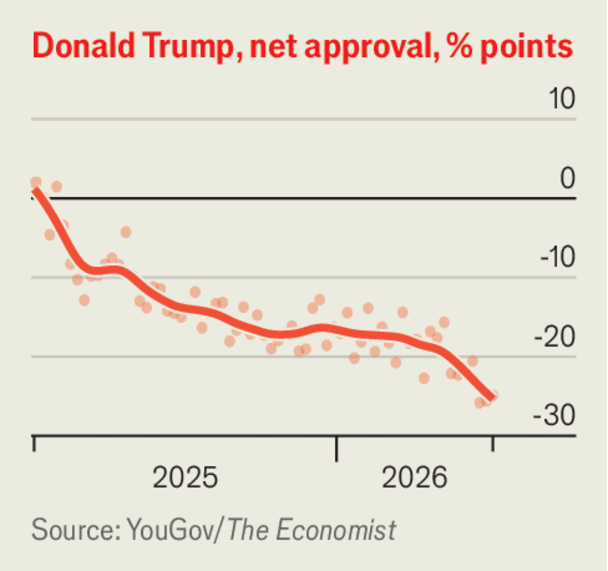
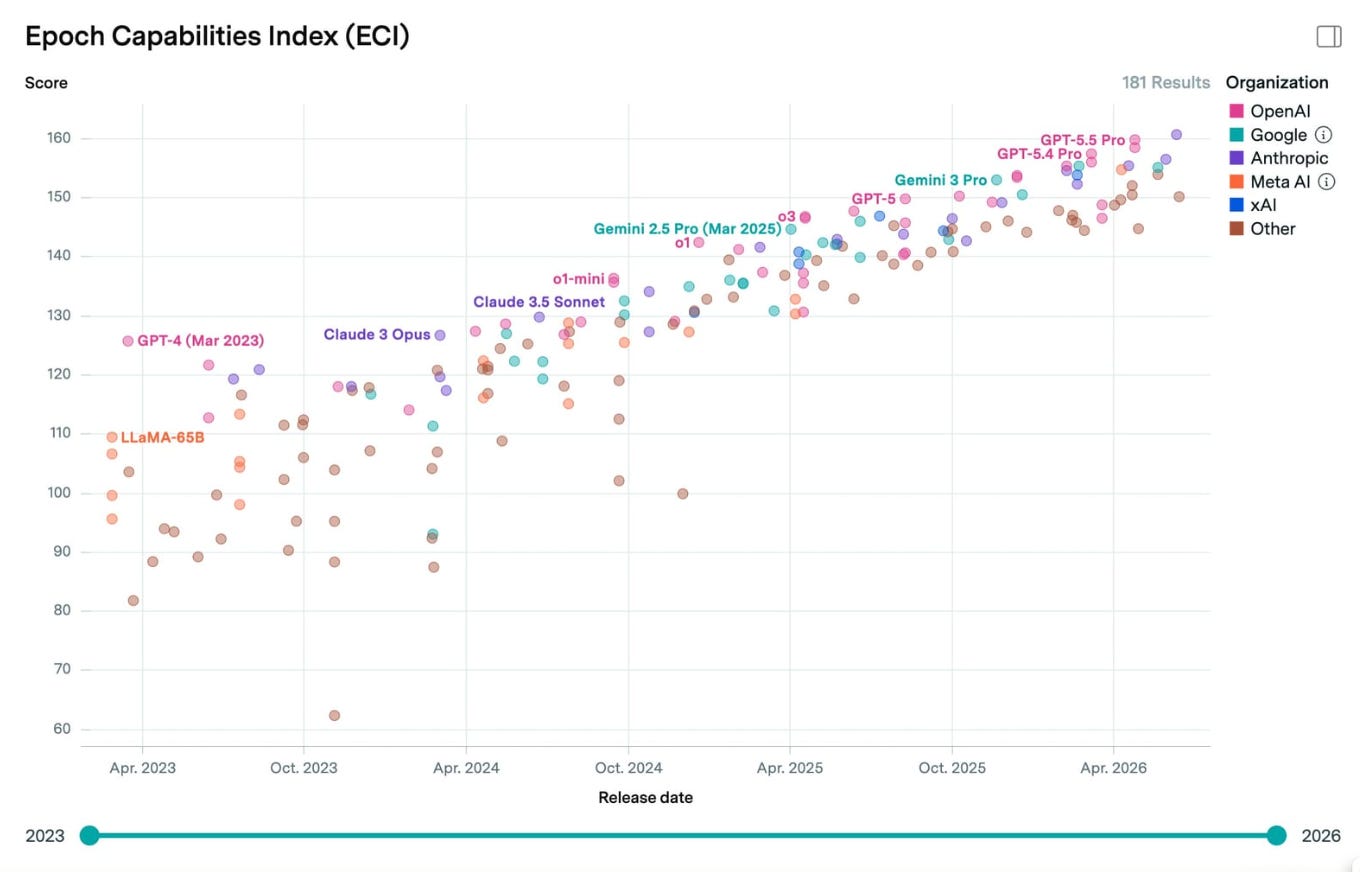
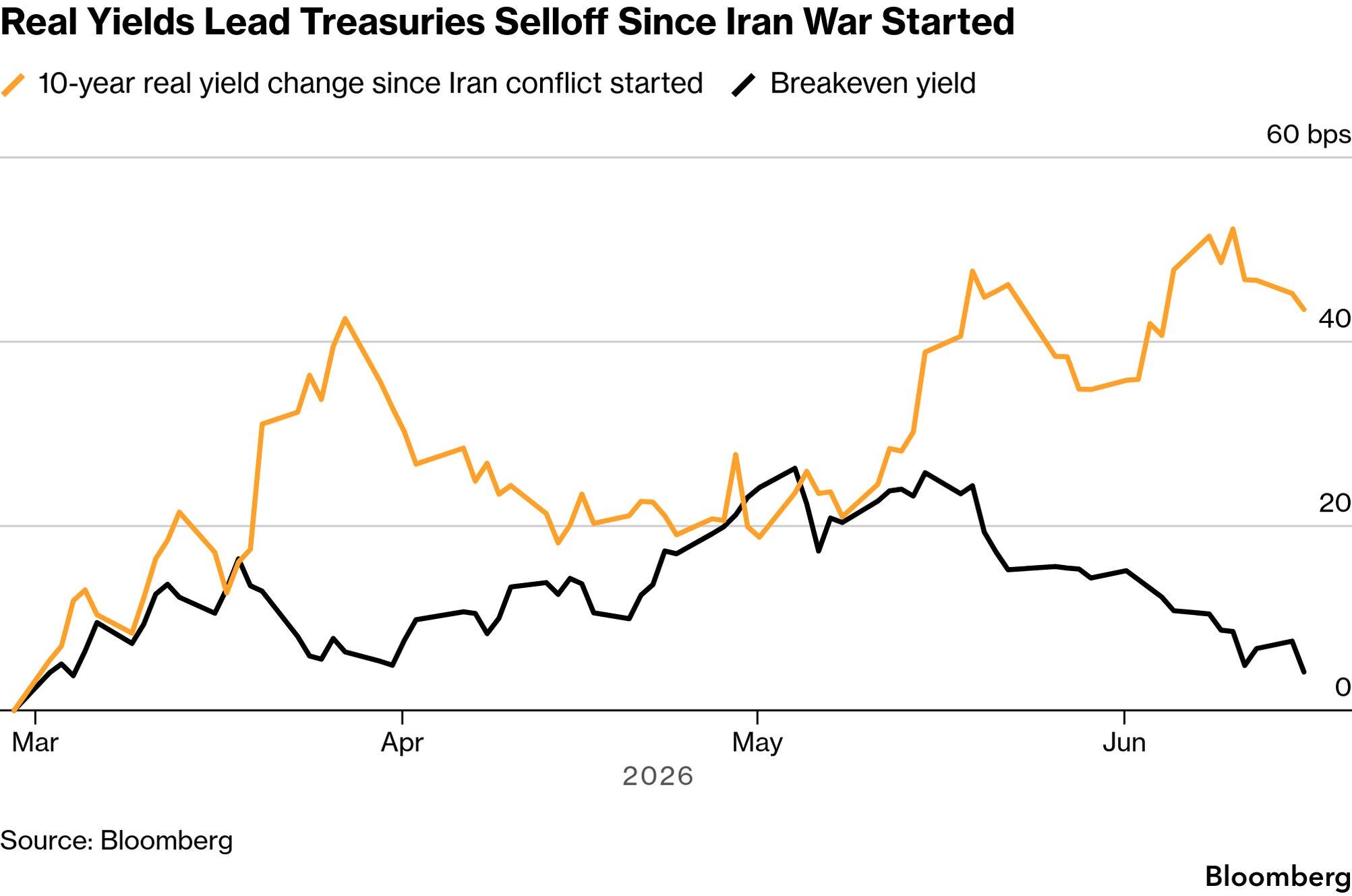
Peering through the veil of time and ignorance, and seeing 24 months ahead via grasping the current deep state of the tech stack: Om Malik as analyst reading the detailed state of chips, networks, and bubbles as a guide to our medium-term future. Om Malik grew up walking half a mile to make a single phone call and ended up reading the global tech stack from the chip level up:
Alas! My friend Om Malik has died. He was wonderful company. He taught me a lot. 60 is much too soon.
Share
I have now lost two good friends on my birthday in successive years. I met him shortly after he moved to Silicon Valley from New York in 2000 to to start his GigaOM weblog <https://om.co/> <https://gigaom.com/>.
Give a gift subscription
Ben Thompson has just let his Stratechery <http://stratechery.com/> interview with Om from 2 ½ years ago out from the vault. It is very much worth reading/listening to to get a sense of the guy as a thinker.
A very brief summary of their conversation, which ties together three decades of tech history:
Journey from Indian kid without a phone to Silicon Valley reporter.
Learning how to read the tech stack from chips upward and to think both bottom‑up and top‑down.
A knowledge of the history of chips, networks, and bandwidth growth lets you “see” 18–24 months ahead in tech—but only if you understand the current state of the stack.
How the dot‑com and telecom bubbles built foundational infrastructure (dark fiber, broadband, cloud stack) that enabled today’s world—that we should think of irrationally exuberance in tech as philanthropy.
The AI boom as a similarly pivotal convergence of semiconductors, networks, open source, and new devices
AI best understood as augmented intelligence that helps humans manage complexity.
About Stratechery: <https://stratechery.com/about/>
CROSSPOST: BEN THOMPSON: An Interview with Om Malik About Tech’s History & Future
<https://stratechery.com/2024/an-interview-with-om-malik-about-techs-history-and-future/>
Thursday, January 18, 2024
Listen to Podcast
Good morning,
Today’s Stratechery Interview is with Om Malik. Malik has been a reporter, analyst, blogger, entrepreneur, and venture capitalist. Malik covered the dot-com era for Forbes, before starting GigaOM, a site that covered the tech industry, in 2001. I consider Malik and GigaOM to be one of my and Stratechery’s spiritual ancestors. Malik then became an investor for True, where he is now partner emeritus. Today Malik writes at his excellent personal blog, Om.co; Malik is also an accomplished photographer, and maintains Photos By Om.
In this interview we trace through Malik’s career, both in terms of tech and media. We cover the dot com bubble, the telecom bubble, and what lessons may be applicable to today. We also look forward to the next few years, including assessing the state of AI, and discuss why Malik is so excited about the Apple Vision Pro.
To listen to this interview as a podcast, click the link at the top of this email to add Stratechery to your podcast player.
On to the interview:
An Interview with Om Malik About Tech’s History and Future
This interview is lightly edited for clarity.
Topics:
Background | Tech Journalism and the Bubble | The Telecom Bubble | The AI Moment | Google and Jobs | The Vision Pro | Qualcomm | Pressure and Success
Background
Om Malik, welcome to Stratechery.
Om Malik: Hey, thank you for having me.
It’s a big honor for me to have you here. If you go back to the beginning of Stratechery — we were just talking before we recorded — but you were one of the people I reached out to, one of the earliest pioneers in online journalism, online writing about tech, and someone that I clearly knew, “If I can make it like Om did, things would be great”. 10 years later, to circle around and talk with you here, I’m genuinely honored, it’s great to have you.
OM: Well, thank you very much. I think you’ve done 10x better than I could have, so I’m really proud of you. From our initial conversation to where you are, I think it’s amazing to just see your progress every month, every week. I just enjoy reading what you have to say, and I admit that I listen to Dithering more than I listen to your podcast [Stratechery].
That’s the idea! Anyone that listens to every piece of content that I put out — it’s a lot! I love you, to be clear. But hey, Dithering is good for some people, Sharp Tech‘s good for some people, Stratechery is good for others. When I did start the podcast, there was a lot of, “Look, I don’t listen to podcasts, if you stop writing I’m going to be very upset.” So hey, a little bit of everything for everyone.
OM: No, I think the reason I like Dithering is because you and John [Gruber] have a really great chemistry. Even if the topics don’t interest me at times, it just is the banter, it keeps me engaged with the two of you.
Well, it’s great because you and John, that’s two of the big inspirations and I appreciate your kind words, but I’m standing on the shoulder of giants, as they say. It’s one of the pleasures of this to be able to talk to someone that from the very beginning you were looking up to and then to have this conversation. So anyhow, we should jump into it. It’s fun to talk to you.
OM: Thank you.
Tell me more about yourself. I knew about you, you started GigaOm in 2001, but before that you were writing for Forbes. You had a very brief stint as a VC, but the story starts in India, correct?
OM: Yeah, so I think for me, my life is I accidentally found myself writing about technology and the Internet. Basically I discovered CompuServe, and as somebody who grew up in India who did not have much communication capabilities, we didn’t have phone, I think I was 14 or 15 when we had a black-and-white television, things we take for granted were not really there. Every time you had to make a phone call, you had to go to a payphone and make a phone call. Every time you got a phone call it was at somebody’s house who lived two blocks away, almost half a mile away. It was usually somebody died or somebody had a baby, those were the only two reasons people called.
I think for me the lack of communication was something which shaped my life and my world view a lot. So when we got a phone, my parents got a phone, I’m from India, so we had a religious celebration, we had a puja in the house, and it was like the whole neighborhood celebrated because everybody had a phone a little closer to them.
My relationships with people changed. I had friends who were not living in my neighborhood and they were living further away, I had school friends I became closer to because we could talk on the phone, except my parents would yell at me that you can’t be talking too long because it costs too much money. I had my first girlfriend because I could use a phone. It shaped my life experience because communication made my world much smaller.
Then I was somewhat older and I discovered CompuServe and then suddenly it was just, “Wait, I don’t have to use a phone to make phone calls or be in touch with people or read everything?”. Something in my head went, “This is it”. By that time, the investigation into what now we call the Internet began and that’s where my journey, and then I came to the US. I ended up working for Nikkei, which is Quick Nikkei News, which is part of Nikkei Group. I wrote about semiconductors for them, my first job was to cover microcontrollers, people don’t even know what microcontrollers are. I got promoted from microcontrollers to SRAM to DRAM — at one time DRAM was like the coolest technology.
That’s right. It was much more interesting than even microprocessors at one point.
OM: Then from there I went to CPUs from CPUs to systems. From systems I evolved into writing about the networks, which was essentially my dream was to write about things like Cisco and 3Com and Bay Networks, companies which people have completely forgotten about. I think that’s what my journey is. So I started essentially bottom up, learned the stack at the chip level all the way through.
Then when I got to Forbes, they taught us how to think through, don’t look for the obvious, go three or four layers beneath the obvious. So you would look at chips and you would try to figure out what the impact is. So the thing is if the price of oil is going up, the obvious story is that the car sales are going to slide and the non-obvious story would be like tire sales are going to slow down, but the Forbes story would be, “McDonald’s sales are going to slow down because there’s fewer people on the freeway”. That top-down thinking of analyzing things — bottom-up from a chip level and top-down from a consumption level shaped me as a journalist, as a thinker.
So I went from Quick Nikkei News to Forbes, Forbes to Red Herring, which was essentially the “it” magazine for a while in Silicon Valley.
Tech Journalism and the Bubble
Well just before we get to that, because one thing that jumps out to me is I opened this conversation describing my admiration for you and I feel like you just solidified it because it was a good articulation of what I want to do on Stratechery, just both the bottom and top down, and also the bit about starting with understanding chips. That’s what I was obsessed with when I was in high school, in college, I was reading textbooks about chip design. All that stuff, I don’t get into that stuff today, but it does feel like maybe that was the reason why I always felt so attracted to what you’re writing about because you can sense just understanding how this works and how important that is. Does that just not happen anymore? Is that just an accident of history? It seems like it would be such a positive quality for covering tech in general.
OM: Well, I don’t know why it doesn’t happen. For me, when I was doing GigaOm, one of the key things, we worked really hard with reporters, Stacey Higginbotham is a perfect example of somebody who loved writing about tech, but she was also bottom-up and top-down. One of the reasons I loved having her in the office was she is a chip nerd who wanted to figure out the implications five years from now, just like what a real tech journalist is supposed to do.
The reason why probably it doesn’t happen anymore is because I think the industry itself has abstracted itself from the real technology. Even your website is called Stratechery, it’s all about strategy and this strategy-level thinking, not about what is influencing the strategy at the very core level. We can think about, we are so surprised with OpenAI and AI and Vision Pro. I don’t know, people noticed three-and-a-half, four years ago, Google was spending a ton of money on Tensor pro chips — it’s like why are they doing it? People were doing asynchronous low power, ASICs, which were low power for Bitcoin and other crypto applications and GPUs for crypto applications, it became pretty obvious where the world was going to be 18-to-24 months from now. We are very surprised that things are happening right now, but the chips always tell you.
I think people mistake Moore’s law for this law of the power of chip, whereas when you look at the chips, you can just see where we are going to be in 24 months. I think I got good training because I got to cover the shitty part of the business. In doing so, I got to learn all the nasty bits about how tech works. I think if you’re a young reporter right now, that’s how you actually have to go up there. You cannot ignore the stack, you cannot just enter at the top level and say, “I understand everything”. If you don’t understand the stack, you don’t know what next 24-to-48 months look like. I’m not saying you have a looking glass, but at least you have a map of where we might just be going.
Or you do have a bit of a looking glass, it might be very dark, but it can be directionally correct, I think that’s a great point. I wanted to interrupt you just because this next period you are now a journalist in the bubble, what was that like just that entire period? So, continue the story.
OM: The bubble was great in two senses. First, the bubble exposed me to the idea of optimism. When you grow up in a Third World country, optimism is not something you’re born with. Your natural instinct is to find yourself in a survival mode. When you come to the US, you are surrounded by optimism. It’s just a country where everybody’s like, “Yeah, we can make shit happen”. I don’t know, that was a default. Everybody around me is like, “Wait, this is how it should be and you come here” and then the bubble happened.
The bubble was like crazy ideas, crazy people, money being thrown around, parties all the time. But really the big takeaway from that was not that there was all this excess, but it was this belief that we have this new thing called the Internet and it could become a bigger and bigger part of life. There was two ways of thinking about it, you could think of it as a bubble or you could think of it as start of something new. Despite the natural journalistic instinct of being cynical and being super cautious, you get caught up — and I did get caught up in that time — it just educated me to look forward and believe in things could be different and it could be better.
All the ideas ended up coming true. The timing ended up being a bit off for a whole bunch of them. But there’s the pet food delivery, all these e-commerce, groceries, all this stuff that is made fun of just in general, it wasn’t wrong, the Internet actually did make all this stuff possible, it made more stuff possible than we realized. The timing ended up being off, but the optimists won in the long run.
OM: There is the reality of now and the reality of tomorrow and they’re never in sync, they never are and they never will be, because we can only make best case guesses today. So if you are an entrepreneur, you’re going to make the best-case guess for tomorrow and you’re going to just go for it. If you’re a journalist or you’re in the media, you’re going to be a little bit more thoughtful and you’re just going to be like, “I’m going to take a little skeptical view of things”, and you do. I think it’s that tension which continues.
I think the 90s, there were so many bad ideas, there were so many crooks. There was a version of SPAC, I forget the name man, like PIPEs, they used to call them PIPEs back in late 90s and they’re now called SPACs. So the movie plays, it’s the same movie, it’s just like Star Wars, the Disney version, Star Wars, the original version. I think the Disney version was bigger and more uglier, but it was really interesting to see. There was a lot of crooks, there was a lot of penny stocks, a lot of nonsense, but there was a lot of great things. Yahoo was a foundational company, eBay is a foundational company, part of global economy. We don’t think about eBay, but it enabled a lot of global commerce and it’s a foundational company.
No, it still is. I randomly, via various friends and acquaintances when I was in the US in business school, suddenly was involved in used parts acquisition on eBay, it’s incredible. I would just help facilitate certain things and ship things on. This sounds really bad or scary — no, it was like some random machine that was built thirty years ago and there’s a spare part in Florida and my cousin twice removed needs in Taiwan. It’s incredible, it’s a huge thing that no one sees or realizes or appreciates how integral it is to the world still today.
OM: Yeah, I think you look at Yahoo even though it’s fallen behind and it’s not part of the conversation, but it was a very important company for a while. Google was ’97, man, people forget the Internet wasn’t really a really big thing at that time in 1997. I think we’ve created some foundational companies during that bubble era, Amazon. Amazon’s impact, whether you agree with it or you don’t is a different story, but its presence is felt in every corner of the planet, it goes without saying. So, that was an interesting lesson each time, I was much more involved in the telecom bubble.
The Telecom Bubble
Yeah. Well that was my next question. I admire anyone that wrote a book. To my mind, writing a book is totally different than writing a daily website because the absence of deadlines I find absolutely terrifying. But yes, you wrote about, it was such a great name.
OM: Broadbandits.
Broadbandits. Yes, which is just a great turn of phrase, but tell me about that.
OM: So that book was all about craziness in the broadband market, optical networking, vendor financing. Lucent Technologies pioneered the idea of vendor financing, the same thing what Nvidia is doing, same thing what Microsoft is doing. Nothing is new, it just is the movie has been played before. But it was just a lot of craziness, a lot of money went into optics, a lot of money went into dark fiber, a lot of it just blew up. I don’t know if anyone remembers Enron and MCI and WorldCom, there was just so many scandals at that time. I just created a little handbook of all the scandals, essentially.
I think for me when I look back, just what came out of that was a lot of dark fiber, a lot of optical technologies which emerged out of that dark time, and now are part of our current — without dark fiber, Google doesn’t have a Google network. Without Google network, you don’t have Google at scale we do. Today Google of 2023/2024 is very different than the Google of 2005 to 2015. That was a pretty incredible machine of technological perfection, a lot of that was enabled by the networks. They bought dark fiber, they bought cheap routers, they bought cheap switches. They were able to scale up because the bubble burst and all this.
So I think, again, from my standpoint, even technologies from that time have slowly percolated their way into our daily lives. Man, 2001, when I started GigaOM, I used to dream of a day when they will be a 10 megabit connection to my house.
(laughing) I stayed in the dorms an extra year around that 1998, 1999 because that was the one place you could get a broadband connection. That was like a T1 connection, which is unbelievably slow, relatively speaking.
OM: So I don’t know if people will even remember, there was a company called Bell Atlantic which became Verizon. They were one of the first companies to offer ADSL, it was a 256 kilobits connection to my house and I had a Dell computer because it didn’t work on a Mac, so I had to buy a PC. I didn’t buy a Dell, I think it was a Gateway. It was a Gateway computer, and that was the first broadband. Then Napster came and then suddenly I had a one megabit connection, I don’t know why it was the case, but again that shaped me.
Early, mid-90s I realized that the faster my network was, the more I used it, the more on it was, the more I used it. So that was a very early realization that this is a correlation between bandwidth and applications as the same as processor, Intel and Windows, and was bandwidth and applications. Then every time bandwidth increased, you were able to figure out there’s going to be a new class of applications. Much better, much bigger, much faster.
Google was perfectly timed, it came at the right time. We all suddenly had anywhere between 5-to-15 megabit per second, that’s when it exploded. Facebook exploded when we were in that 10-to-50 megabit reality. There’s companies, because we have more network and more always on network, the more we use it. Mobile was the same thing. Your “everywhere Internet” means you’re going to use it everywhere. I think that was a foundational learning of a bubble for me, all those things.
So you could have easily gotten dark about everything, and I was just like, “No, this is amazing”. The worst thing I’ve ever written, John Doerr had made a comment saying that the Internet is the greatest wealth creation opportunity in the history of mankind, I wrote a piece for Forbes.com which was another foundational, we were the early guys on the web, we were doing web publishing so early, I wrote that piece and I mocked his comment. Until today, every time I meet John, I apologize for that because he was so right and I was so wrong, because I was thinking like a cynical person with a very limited world view, not thinking where we could be.
I think the bubble’s big lesson for me was, and both the bubbles, the Dot Com and the telecom world, it’s not where we are, but where we could be is the hardest thing to imagine. You have to do that if you live in the world of technology. Even if you’re a writer, even if you’re cynical, you still have to believe in where we could be.
But the parties were great, parties were so much better. The current generation of founders, they don’t even know how to party. I’m not going to go any deeper than that, but these guys are such amateurs.
(laughing) Well the thing about a bubble is it really is a perfect thing to highlight that difference in worldview that you talked about. If you’re going to be a journalist looking at today, and if you bet that it’s going to fail, you’re probably going to be right versus an entrepreneur guessing at what the future might be and if you hit, it’s going to be fabulous.
What a bubble does is if you’re in a certain place today and you need to get to another one, there’s a lot of stuff in the middle that is actually not economically beneficial to build in the short term. So a bubble inspires all this building that in the short term turns out poorly, it’s a poor return on investment but the externalities of that building are massive. To your point, it didn’t make sense to build out all the fiber, all this dark fiber when there were no applications to use it but because it was built out, the applications could then be built, it was the spur there.
The AI Moment
The question is do you see a similarity today with what’s going on with AI, with GPU build outs, all those sorts of things? Where would you put us in the 90s if we’re in a similar cycle?
OM: I think we are post-90s. I hinted in a post I wrote towards the end of the year was that this is the most excited I’ve been in twenty years. I’ve been waking up in middle of the night making notes, literally last night I woke up at 2:00 AM and I wrote in my journal for three hours, mostly because I could not stop writing down the questions I have.
The way I see it, last year you could see, in 2003, you were there, and you could see there were pieces like the jigsaw was being set, you had a little bit of social, a little bit of open source, a little bit of always-on network, all those things were coming towards each other towards what was going to be a Web 2.0 post-social Internet. [Palm] Treo was coming around and suddenly Blackberry had more Internet in it because the 3G was pervasive. Things had started to happen, they were not complete, but they were all coming together.
2023 was the same year, in my mind, it was like we’ve seen a lot of converging trends. The semiconductors are suddenly coming to market, the AI chips are coming to market, the networks are becoming more robust, the 5G is becoming more pervasive, there is more satellite connectivity.
By the way, for the record, 5G gets dumped on a lot, it is actually different. With 4G, you still knew you were on 4G relative to WiFi. 5G, there is a level of seamlessness that of course is only going to increase. I just mention that because it gets made fun of because it was so hyped up and it was very easy to dismiss it, but it speaks to your point, it is a change under the surface that you don’t feel, but it does change how you act, I think that’s worth calling out.
OM: The thing with networking technologies is that they’re so invisible. The only time they become visible is when they don’t work. The last time you thought about your WiFi is when it was not working, or you curse T-Mobile because you lost connection, not because it’s working.
Well, this is an advantage of being in Taiwan, because I have perfect 5G coverage basically everywhere. So you go back to the US, which is so much more spread out, so much less dense, and it’s jarring to just shift from a mindset of constant high bandwidth 100% of the time to having to be cognizant of it all the time. It’s a mental burden that I think most of our listeners are living with and they don’t even realize that it’s there, this is one area where I do feel like I live in the future in that regard.
OM: I get about, I don’t know, it’s like over 200, I can check, it’s close to 100 gigabits.
You’re in Silicon Valley. I could promise you when I’m in Wisconsin, I don’t get that.
OM: Again, I take your point because you’re a smaller country, you have much easier to cover. 5G got hyped because it was supposed to be this wonder drug for everything. It’s just a network, man. It’s a much faster higher capacity network which is slightly better than 4G. The phone companies had to hype it because they have to make money selling it.
So you have all these pieces coming together in 2024.
OM: Without this high speed network, you don’t have devices which are going to be all around us, whether it’s Vision Pro or AI Pin or Rabbit or whatever you want to call it, or Waymo or anything, you need network presence, you need connectivity. We need those networks to become so much better to reduce latency so these applications can work. Again, the stack conversation, which no one in Silicon Valley wants to have because they probably have never even thought about it, but that’s the reality of it. Somebody asked me, “What is the biggest problem with the AI Pin”? It’s like, dude, they’re on a T-Mobile network that’s got a 50 millisecond latency, 50-to-100 millisecond latency. Just imagine asking a question and waiting for that long, that’s not how AI is supposed to work, the latency on OpenAI is the single biggest problem right now.
You can see, especially when you have voice enabled, you can feel the future. But it’s so painful and slow to get into there, you really have to cast your mind forward to feel that. I think this gets to, when Amazon announced the latest version of a Thin client, you wrote a post saying, “Nope, not going to work. I’ve been here, I’ve been seeing this for thirty years.” I think it gets to this point, you need multiple pieces because the networking, it’s way better than it used to be, but there is some aspect it’s still never good enough. It’s probably the single biggest limit or even more, it’s what chips used to be in the 90s, that’s what the networking speed is today.
OM: Well, I think that right now, if you think about the latency experience right now, it reminds me a little bit of how we used to have dial up. Things were a little slower and eventually things happened and then things gotten better. So, things will improve, I 100% believe that we are going to see improvement in network quality, because the phone companies and all these guys have to make a living so they will have to improve the network performance.
I think the biggest reality check we need to have in all these devices is that we are expecting instant perfection today as consumers, because we’ve gotten used to it. Look, Sun introduced the idea of a network computer in the 90s, 2010 is when iPhone 4 came out. iPhone 4 was the perfect cloud computer, we don’t think of it because it looks like a phone, it’s called a phone, but it’s a cloud computer — every Android device is a cloud computer. It’s pretty pointless if it’s not connected. The vision came true, not exactly how they envisioned it, but it did.
That’s why I think of it OpenAI may be the pretty young thing of today, the world ten years from now will look very different whether that is the company, that is the way we interact with information, not really, but we have started walking on a path which is going to take us somewhere else. That’s what is exciting.
I feel the same way. I’ve remarked before, a couple of years ago I was feeling pretty burnt out. I abide by the idea it’s not a function of how much you’re working, it’s a function of how much you’re working on stuff that you’re interested in. I found myself writing about congressional hearings and regulation and all these things, it was not very enjoyable. Number one, I stopped doing that so much, that was the big change. But then number two, the last couple of years, and I want to talk about both AI and the Vision Pro, which you’re tremendously excited about, but I don’t think it’s a “me” thing, I think it’s a technology thing, this is incredibly exciting.
Let’s start with AI. What do you think is going to happen this year and what do you think is going to happen in the long run? What gets you waking up at that in the night to write three hours of notes?
OM: Well, I think that’s the key thing is we think about AI through the lens of just one company right now, which is the zeitgeist, they’ve captured the zeitgeist, so we all think about OpenAI as AI.
When I think of AI, I think about how we live in a very complex technology reality right now. We are connected all the time. Our apps are so busy, our data, how we interact with information is very different today than it was twenty years ago or even ten years ago. So we as humans are finding it difficult to deal with the data we have around us. This is our personal data, you’re not looking at what information is out there, what you’re reading, just what you’re doing on a day-to-day basis is becoming more and more complex. Just try and do banking or use PayPal and just the whole thing, you start to see we really need help.
That’s how I feel the software taketh and software giveth away, so my AI idea is that it’s not artificial intelligence, it’s augmented intelligence. It’s going to do a lot of grunt work which we are incapable of doing or we are too lazy or we don’t realize we have to do, for us. If we start to think about that, then you start to see newer clouds of applications come to fore. Completely different way of writing, why do we have to write in a certain way? When I think about AI, “Why do I have to edit photos the same way I was doing fifteen years ago using the same Lightroom?”.
Because your photos are amazing and you better not change anything, that’s why.
OM: The point is there is so much more, but we are taking hundreds of photographs every day, whether you have selfies, this and that, we don’t know how to sort through it, we don’t know what was the great photo so this is where you need technology to help us. You can call it AI, you can call it augmentation, whatever you want to call it, so we are going to see this is just a next level of software improvement is how I see it. I’m just trying to figure out, “Where can it be, where can it get better?”, before we get to a point where there is a platform-type company which is like Facebook or Google or Apple, I don’t think we are there yet, we are just starting out on that journey.
But it’s so exciting, and what is different compared to the past, 2003, is we have a lot more open source efforts going on here, that’s a new thing for the planet. More importantly, we have a different reality of media. There is YouTube and there is GitHub and GitLab and all these things so if you are somebody who wants to learn, I’m learning AI, all these things, by basically being on many Subreddits and watching YouTube videos and UDME and all these things. So even somebody who’s of my age who’s not an engineer can go out and start to figure things out. I think that, plus the open source, to me that’s good raw material for even more innovation.
It’s such a good call on the open source bit where it’s just a given. The debate is no one doubts that there’s going to be open source alternatives, and that was not at all the case twenty years ago — you had Bill Gates calling the open source movement communist. I think that venture capital was very skeptical of, “Is there any worth in investment here?”. Now though the barrier to build has lowered so much. You don’t need to go out with a pitch deck to get money to even get started, you can just literally start building right now, AWS, get some credits, or you don’t even need credits because no one’s actually using your application to start out with. All of these economic factors and this existence of things like open source, it really is a profound change. It’s one that, until you said that, it’s hard to realize what a stark difference this is from the last time around.
OM: Think about the 2003 timeframe. We had PHP, MySQL and Apache server.
Good old LAMP.
OM: Open source LAMP stack, that thing changed the Internet, no one even talks about it anymore, but that was just four pieces of open source software that completely reshaped where the Internet was going to go. People forget that there was a time when you had to spend $2 million to spin up your web infrastructure buying Cisco routers, Sun servers, or buying licenses from Microsoft, it was insane, now look at where we are now. Then suddenly LAMP comes around and it’s free. So there are people hosting websites and then people creating blog software like WordPress, it’s just free and that’s open source, then guys like me actually have a business. It’s like, there you go.
Stratechery is completely and utterly dependent on open source. There’s no way from all the software, but then that made the infrastructure possible where you could just set up a server and you could go rent it. You didn’t need to have one in your garage because they didn’t have to worry about licensing costs of supporting whoever wanted to sign up. The whole freemium model is all dependent on this, it’s an astronomical shift and a very positive one.
OM: Well, I am really excited about all the open source stuff. I’m excited about all these open source people are experimenting with putting LLMs on Raspberry Pis and watches. I’m just like, “Dude, I’ve seen this movie before”, just in a different context and it’s very exciting.
It’s fun.
OM: That’s it.
It’s fun for us to write and talk about it, it’s fun for people to develop, I think there’s probably an aspect where AI is just a tremendous boon to open source because it’s fun and interesting. “Let’s see if we can get Llama running on an iPhone”, “Let’s get it running out of Raspberry Pi or Mistral”, or whatever it is. That’s super important.
OM: I saw this young kid from Rabbit AI making his presentation today at CES launching his new device, I haven’t seen that in forever, I haven’t seen a young person get up there and announce a new product in a while. It’s exciting because I don’t care whether that becomes a billion-dollar company or it becomes the next Apple, that’s not the point. The point is there is somebody who believes in doing things differently and that’s what I find exciting. I think if you’re a storyteller, that’s exciting. If you believe in technology, that’s exciting. If you’re a naysayer, that’s not exciting.
Google and Jobs
So, just a specific strategy question. You talked about augmented intelligence versus artificial intelligence. One of the examples you use as we take hundreds of photographs in a week or a day or whatever it is, and how do you even sort through it? Is this an area where maybe Google is a bit better placed than you might think? Not because of Google search and adding in an LLM, but because, and this is a vision they’ve put forward very clearly at Google I/O and to your point, their CapEx has gone up as a share of revenue and it started many years ago. That’s their pitch, “We’re putting AI into products that people actually use”. Is that compelling to you?
OM: Yeah. Look at their Google Maps, I think Google Maps is one big giant early AI experiment. It’s pretty good, take it away from your phone for a day and I want to see what happens to you.
It is in my dock.
OM: Yeah, it’s like you can’t get anywhere without Google Maps and the directions so I think I have very strong opinions about Google.
Well, you can let them rip.
OM: I think the company is so hampered by its economic reality. Google is where AT&T was in the past when it was part of the Internet revolution and the semiconductor revolution. It birthed a lot of new technologies with Bell Labs, it’s the same thing with Xerox, same thing with IBM. They are so weighed down by their own past with their own ten blue links. They’re trapped in it, for a company which has everything.
If you look at what they have done, Waymo, only Google can do — advertising dollars paid for Waymo, there is no other company in America which can do Waymo, I can guarantee you that. Not a single company, not Microsoft, not Amazon, not Apple. They pursued that opportunity for almost twelve years and they went after it, I think that is a different Google than what we have today.
Now, they just have, “How do we monetize this one machine as much as we can?”, which is the advertising. I think that’s a bigger problem they have than anything else, but we don’t have enough time to go into that, maybe another time.
Well, I’m going to take that as an invitation to have you on again soon because you’re right, we could do an entire episode about Google.
OM: Yeah. I think that company is in need of a reboot, a refresh, I think it needs new leadership. It really needs to take some bold decisions, but all big tech companies now basically exist for making sure everyone’s 401(k) stays up and up and into the right.
Up and to the right, yeah. Well, that’s a really great point. One of the things I wrote about back when Apple’s stock was, not slumping, but it wasn’t growing like it was, but the iPhone was so clearly this massive thing. This is probably just misguided in the history of Silicon Valley, but can we shift at some point to more cash compensation and away from the stock issue? I think it’d be the strategic benefit of these companies to insulate them from some of this pressure. Now, probably not realistic for lots of reasons, including the competitive space of Silicon Valley and people can change jobs and all these sorts of things, but what you just said with the 401(k) strikes me it’s basically the same problem. It’s not just that they’re worried about their employees being happy so that the stock price is going up, every person in America is dependent on their stock price going up, but that’s remarkably limiting.
OM: Yeah, I think this is where I wrote a piece about Apple and Tesla and all these big tech companies being part of S&P 500 and being part of many index funds, which by default makes them really relevant to our retirement funds, every single American, I think people don’t contextualize that. There’s a lot of people who hate on big tech, but at the same time also don’t realize very clearly that you can hate the company, but you are also benefiting from it. I think it’s really weird. My favorite phrase is stolen from Mark Zuckerberg, which is, “Everything is so complicated.”
I feel that we are going to see a lot of improvement in things, which technology does better than us. It’s going to be disruptive, there’s going to be job losses, realignment of society, people who’ve been used to — if you’re an x-ray technician, there’s a lot of X-ray technicians in the hospitals, what if the AI replaces them? What will they do? What happens to radiologists and radiology technicians? That’s just in healthcare.
You start to see what happens to people who write marketing copy and our people who are in call centers in India, they have not really internalized that this is coming. AI is going to change the need for bodies very drastically. So there’s a lot of compression which is going to happen because of it but it’s also going to force people to think differently. How are you going to create new opportunities? I don’t know, I don’t have the answers, that’s why I said I have more questions than I have answers. So that’s why whenever I write down a question, I’m looking for an answer, somebody probably has an answer. I read a lot, I listen to a lot of people and hopefully I think there’s smarter people out there who are thinking about this thing.
I believe in the creative energy of smart people to figure out what the future looks like, at least from an employment standpoint but I definitely think that there’s going to be some compression, but we need to do things better in certain areas. The medical system needs some help from a technology standpoint, same goes for transportation or how we do a lot of other things. For God’s sake, I could use AI to remove dust particles on my photos, that’s the biggest time suck in my life right now.
The Vision Pro
It’s very true. Well, there’s one other topic I do want to get to. Last week Apple announced that the Vision Pro is going be available for sale in early February. I think you’re the one person that is even more enthusiastic about the Vision Pro than I am. What we do share in common is that we’ve both used it. I’m not sure I’ve seen a greater divide ever than between people who have used the Vision Pro and people who have not, and how that impacts their evaluation of this product. Why are you so excited about it?
OM: I think this is the TV of the future, forget the productivity. Games, Apple’s not very good at games, they may have a lot of gaming business, but they’re not very good at games.
By accident, yes.
OM: This is going to be a great media consumption device. This is going to redefine how we interact and consume media, especially the visual media, where it is static. I definitely think the spatial photography is going to create a whole new photographic art form, which is post the flat two-dimensional photography. I’ve watched five minutes of some TV program on this damn thing and I’m like, “Why am I going back to my iPad?”, it makes no sense.
But the thing is you actually have to be mobile-native to actually appreciate something like this. So if you’ve grown up watching a 75-inch screen television, you probably would not really appreciate it as much. But if you are like me who’s been watching iPad for ten-plus years as my main video consumption device, this is the obvious next step. If you live in Asia, like you live in Taiwan, people don’t have big homes, they don’t have 85-inch screen televisions. Plus, you have six, seven, eight people living in the same house, they don’t get screen time to watch things so they watch everything on their phone. I think you see that behavior and you see this is going to be the iPod.
The headphones, why is headphones selling all the time everywhere? It is because people want their moment of privacy and they want to be alone and they want to listen to their media in their way. I think that’s what Vision Pro excites me is it’s going to be a video consumption device. I watched five minutes of, I think it was Ted Lasso. I’m just like, “Wait, I want to watch this series”. I haven’t seen Ted Lasso, it was like a hundred-foot screen you’re watching a TV on, it was like, “That is pretty dope”. That’s a reference design movie system on your face, that’s what I feel is the exciting part.
The funny thing is I’ve been writing about it for five years, this is where the TV has to go because demographically that’s where we are all headed. More and more people live alone now and they can watch things in devices like that. I also feel that we haven’t really looked at Vision Pro from a creator standpoint. When you think about it, I want to watch Golden State Warriors from courtside, I can’t because the tickets cost like $10,000, but I can watch it on Vision Pro if I pay extra $10 or extra $20 to sit courtside. NBA can sell that same court side ticket a million times, 10 million times. Or the same thing with IPL [Indian Premier League], I want to be on the front row of the game or I want to be in the center court of tennis. You change the relationship you have with content completely, suddenly you are immersed in content. I think if you are a sports League, you’re looking at this as additional money, this is additional money.
Similarly, I’m looking at this and just like give me a movie. I want to see a concert in this, because you go into a Taylor Swift concert, you can’t really get in the front. You’re sitting in the back and it’s a great experience, it’s great being there, but you’re not really there. Now you can be there without being there. I think that’s why I feel like once people use it, they will actually see, “Wow, this is the best TV I’ve ever owned”.
I don’t watch a lot of TV in general so I haven’t focused on that as much. I love the multi-screen thing. I have like 4 to 5 screens around here and I’m going to be traveling next week and I would love to have a Vision Pro to get the expansive workplace that I like to work on so I do think about the productivity thing. But you are right, in the demo, what is the mind-blowing aspect is the entertainment bits. You had a beautiful post about the evolution of movies and going to drive-in theaters and then going to multiplexes and then you can have these big screens in your house. That bit you touched on, on combining that experience, that fidelity, with mobile where you can do that anywhere is number one incredible, but then number two, you mentioned the sports bit — that was the part that got me, that’s the part that I care about, that’s what I use TV for. I watch a lot of sports, when I experienced sports in the Vision Pro, it was unbelievable. This was a five-second snippet of an NBA game, that five seconds was one of the most mind-blowing experiences that I’ve had.
I think because that mattered to me, and when you experience the stuff that matters to you in this environment, it is so much more immersive than I think you can realize, this gets to I think the spatial images videos thing. Speaking of Gruber, he talked about how he was able to try it with his videos or with his images. Yeah, it’s one thing to watch people on a campfire that Apple provided you in the demo, which is what I saw, but then you bring in your kids, your experiences. Yes, it’s easy to be cynical and point out, “How are you going to capture it? Is it going to have dad with a mask on or whatever it might be?” — it’s a miss of where this is going to go. Of course it’s going to get easier to capture and that experience is, again, everyone’s going to be experiencing it in a few weeks. It’ll be nice because they’ll see what we’re talking about.
OM: Yeah, I think so. I think again, this is still early days, there’s a lot of work which needs to be done. I think a little bit of, “What is the missing social element?”. I think Apple is just one of those companies that doesn’t understand social, just like it doesn’t really understand the Internet, I don’t know if they’ll probably understand AI. But they understand a great compute experience, and I think that’d be interesting.
That said, I think you asked me what’s the similarity from twenty years ago. I say that twenty years ago, dude, iPod was just taking off at that time, it changed our relationship with music. We listened to music more often and we changed our idea of what is fidelity of music because we were listening to iPods, and we also created a more personalized music experience. The idea of a mixtape became so much easier because of iPod. Fast-forward to where we are today as a society, our entire society is a mixtape from the morning until the end of the day. We have our own filter bubble, we’ve got people who read Casey Newton and people who read other people and there’s people who read you. That’s how we create our daily reality, which is our own mixtape. I think we’ve forgotten how far we’ve come.
I think 2023, we suddenly started to see a mixtape version of information, like how we are interacting with it. 2014, I did a conference and I talked to one of the key people [K.K. Barrett] behind the movie, Her, on stage, and I had a long interview with him later. What really got me about that movie is that we all have such a tough time to put ourselves in the shoes of other people, we have a tough time understanding that if you don’t have a family and if you don’t have kids or if you don’t have —
Or if you’re in India and you don’t have a phone.
OM: Yeah! You don’t understand what technology does for you or what technology means to you or how it comes into your life. I am the kid who had to walk half a mile to make a phone call. Basically, I talk to my mom on FaceTime every day, sometimes multiple times a day to the annoyance of my own self. When you think about it, if that’s not progress, then what is?
I wrote a piece recently about what happened to optimism? Why did we stop being optimistic? It’s not about money, it’s not about being rich or successful, it’s just a whole series of people, and I know a lot of them worked on this video Internet technology to get to a place where we have FaceTime. It’s a thirty-year journey. I was there for the earliest experiment with Jeff Pulver, I was there for Skype and look where we are today. Now, I’ve seen people walk on the street just doing video calls on either WhatsApp or on FaceTime or Google Video or whatever.
I think where we are is sometimes it’s really easy to take things for granted and not feel that we’ve come a long way. We have, we are going to go a long way. If this pandemic has taught us anything, we need science and technology to help us figure out all the problems we are going to have in the next few years. There’s going to be more pandemics, there’s going to be more diseases, there’s going to be more climate-related challenges. How are we going to fix those? We need some help, like augmentation or augmented intelligence is part of that. So it’s a slightly different way of thinking about the world.
But before this, for three, four years I could internalize Bitcoin. I could internalize Bitcoin production using specialized chips because it made perfect sense that in the future we will do that. It made perfect sense for GPUs to be used for high intensive applications and how they could be used to do other things. But the grift in the middle reminded me of the penny stock and the raging bull phenomena of the 1990s and the SPACs, the NFTs.
You look at today, the Vision Pro, Vision Pro is there. Five years from now there is not Vision Pro, but there is 10 different types of devices like that. One of my favorite photographers is a guy called Reuben Wu and his images are essentially three-dimensional images, in my opinion, and spatial images. He could be creating a spatial image and an NFT-like authentication service, authenticating it to sit on my Vision Pro desktop to be looked at whenever I want. A certain micropayment goes his way for every time, I can buy it. The thing is, it’s like there is no grift involved in it, it just is AI.
AI and the infinite production of content makes the case for digital scarcity. There are all these sorts of pieces that are coming together.
OM: Right. I think the grifters got more attention because it’s easier to pay attention to the spectacle of technology than to the technology.
It’s easier to grift than to build something.
OM: You were asking me earlier, “Why am I writing more?”. It’s because finally all the tourists have gone home and the real technologies have shown up and this is what I’m here for.
Well, I already had a whole list of more questions I wanted to get to. That last bit inspired multiple more, including the Facebook VR, all the social bits, but we are at an hour. I would love to have you on again sometime soon. I think this was absolutely fantastic to hear your story and now that set the stage for us to really explore what’s next at some time in the future.
OM: Yeah, thank you Ben for having me. Again, congratulations on all your success.
Well, thank you. Thank you for coming first and giving — I already said it, I’m not going to say it again — but it’s a real pleasure to have you on.
OM: Thank you.
<http://stratechery.com/about>
Subscribe now
Leave a comment
If reading this gets you Value Above Replacement, then become a free subscriber to this newsletter. And forward it! And if your VAR from this newsletter is in the three digits or more each year, please become a paid subscriber! I am trying to make you readers—and myself—smarter. Please tell me if I succeed, or how I fail…
##crosspost-ben-thompson-an-interview-with-om-malik-about-history-future
##silicon-valley
##crosspost
#ben-thompson-an-interview-with-om-malik-about-history-future
#ben-thompson
#an-interview-with-om-malik-about-history-future
#om-malik
#ben-thompson
#tech-stack
#augmented-intelligence
#open-source
#techno-optimism