Local LLM Performance on a Maxxxed-Out M5Max MacBookPro: TABLE OF THE DAY
Note on the state of the OpenClaw installation: speed & coherence & memory footprint & semantic depth in homarus cyberneticus. What local LLMs can (and can’t) do effectively right now on sub-dining-room side-table consumer hardware…
I confess I did not think the idea that I would ever have a cybernetic assistant lobster with a swappable software brain had entered my mind before last month.
A report from the front lines of trying to run an agentic OpenClaw locally on Apple’s M5Max silicon: load latency, memory footprint, tokens per second, simple coherence, and what epistemic density: the ability to sustain a simulacrum of a logically serious argument.

On a machine with 128GB of unified memory, 600GB/s of memory bandwidth, and perhap 70 TFLOPS FP16 of raw LLM-relevant computational power (cf.: 350 for an NVIDIA RTX 5090, but with four times the memory), we have:
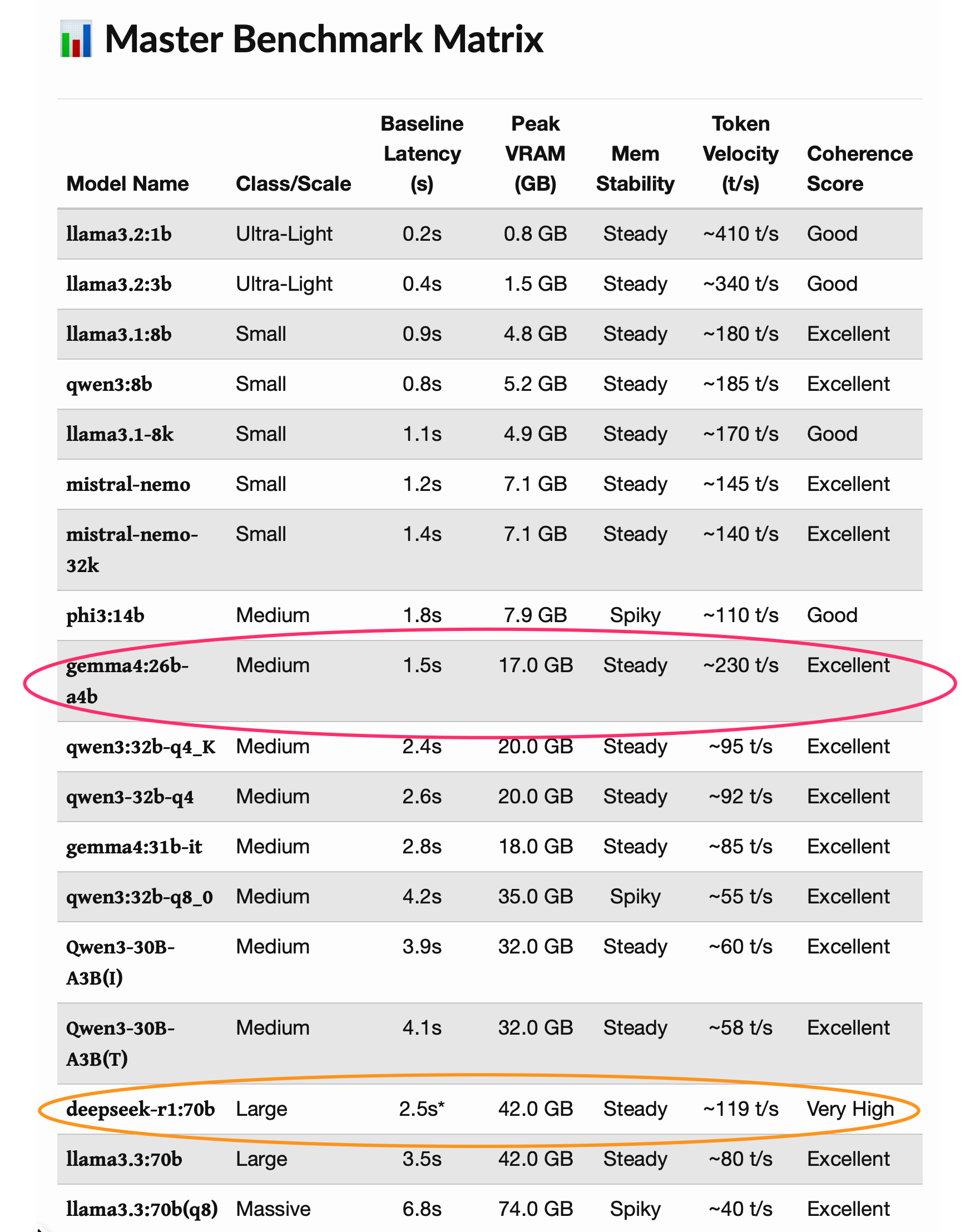
Notes:
The absolute gonzo gemma4:26b-a4b-it-q4_K_M performance-wise. What is going on here that is making it such an extraordinary outlier?
deepseek-r1:70b as the secondary performance-wise champ.
The low initial latency: the absolute speed with which all these models initially load.
Speed demons: For background tasks, logging, or simple classification, thellama3.2:1 and llama3.2:3b can do a huge amount of very simple summarization and classification tasks at rock-bottom resource costs and remarkable speed.
Coherence is very important: Speed is how fast you arrive; Coherence is supposed to be whether you arrived at the right destination.
The Coherence Score is supposed to be the model’s ability to maintain structural integrity, logical consistency, and semantic relevance over a sustained period—follow the prompt’s constraints perfectly, maintain a stable “train of thought,” and not succumb to common failure modes like repetition or hallucinated syntax. The “Coherence Score” is supposed to tell us whether a speed gain is actually a utility gain or just a faster way to produce garbage. As I said: speed is how fast you arrive; Coherence is supposed to be whether you arrived at the right destination.
There is, in addition to initial load latency, memory consumption, speed of token generation, and ability to maintain the simulacrum of a coherent train of thought, another dimension of performance: call it semantic depth or epistemic density.
Semantic depth is “reasoning”, “knowledge”, and “logical complexity”. It is more than coherence, which is simply “not spouting obvious nonsense”. The 5GB RAM models can follow simple instructions like summarize this text. However, ask analyze the economic implications of the Anthropic/DoD rupture and how it might impact the valuation of OpenAI, the 5GB RAM models will fail to produce anything that would pass any Turing test. They will produce coherent-sounding sentences that are factually untethered from reality. The models squatting in 17GB or 74GB of memory with their massively more parameters sound much better.
A 5GB model can stay on topic for 50 words or so, but will struggle to maintain complex constraints over 1,000 tokens. If you give a complex instruction involving multiple negative constraints like explain X, but do not use the word Y, and ensure the tone is wry, yet avoid any mention of Z, the 5GB model will almost certainly “forget” one of those constraints. The 17GB or 74GB model has a much higher “instructional inertia.”
Right now: llama3.2:3b appears to be the model for: is this email urgent?qwen3:8b appears to be the model for: summarize this 5000-word article. llama3.3:70b(q8) appears to be the model for: let’s write or debug some computer code. gemma4:26b-a4b appears to be the model for nearly everything else.
There ought to be a place for deepseek-r1:70b. Deepseek itself suggests that it is good for “complex analysis/research (e.g., ‘synthesize these 5 papers’) and other tasks that require massive reasoning depth and factual density. But while llama3.2:3b is a worse-but-faster email classifier than I am, qwen3:8b can produce an acceptable summary note for my files freeing me up to live my life, llama3.3:70(q8) is a better python debugger than I am, and gemma4:26b is an effective LLM workhorse, I have not yet figured out a useful workflow process in which deepseek-r1:70b is better than just doing it myself.